Look at this. Just look at it. This is what happens when you let people “vibe” their way through coding instead of learning how computers actually work.
What the Hell is Vibe Coding?
Vibe coding is the latest plague infesting our industry—a mindset where developers treat programming like some kind of abstract art form, where “feeling” the code is more important than understanding it. These people don’t optimize, they don’t measure, and they sure as hell don’t care about the consequences of their half-baked, duct-taped-together monstrosities.
Instead of learning how databases work, they just throw more RAM at it. Instead of profiling their garbage code, they scale horizontally until their cloud bill looks like the GDP of a small nation. And when things inevitably explode? They shrug and say, “It worked on my machine!” before hopping onto Twitter to post about how “coding is all about vibes.”
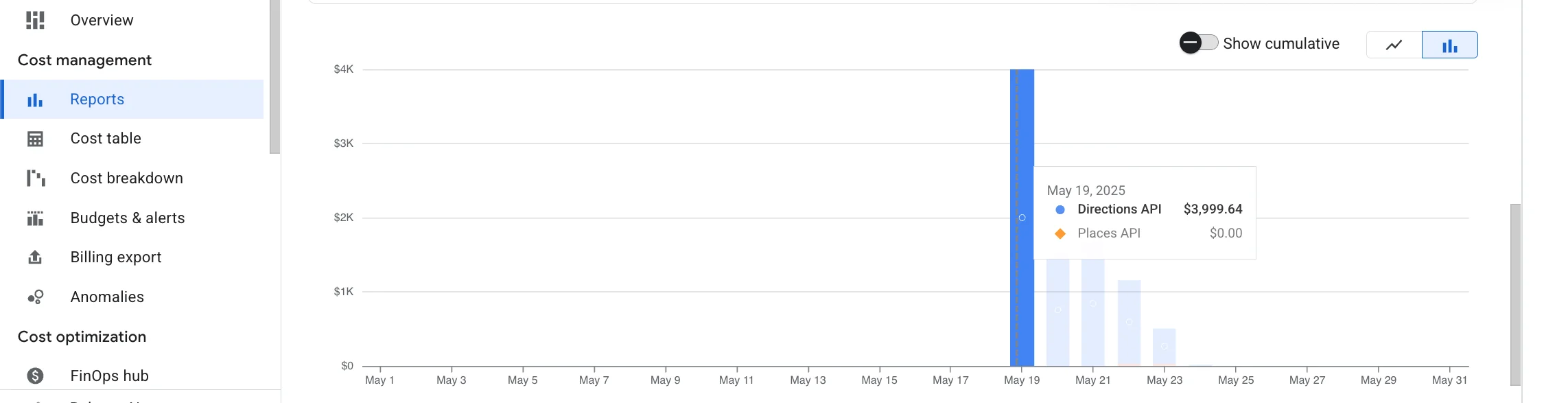
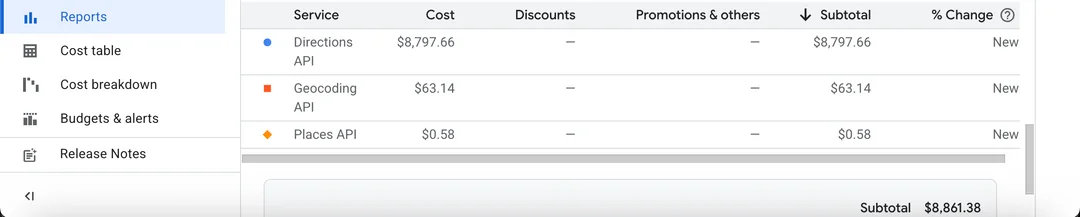
Vibe Coders Are Why Your Startup Burned Through $1M in Cloud Costs
The screenshot above isn’t fake. It’s not exaggerated. It’s the direct result of some “senior engineer” who thought they could just vibe their way through architecture decisions.
- “Why use a cache when we can just query the database 10,000 times per second?”
- “Who needs indexes? Just throw more replicas at it!”
- “Let’s deploy this unoptimized Docker container to Kubernetes because it’s ✨scalable✨!”
And then—surprise!—the bill arrives, and suddenly, the CTO is having a panic attack while the vibe coder is tweeting about how “the cloud is just too expensive, man” instead of admitting they have no idea what they’re doing.
The Cult of Ignorance
Somewhere along the way, programming became less about engineering and more about aesthetic. People treat coding like a personality trait rather than a skill. They’d rather:
- Spend hours tweaking their VS Code theme than learning how their HTTP server actually handles requests.
- Write 17 layers of unnecessary abstraction because “clean code” told them to.
- Deploy serverless functions for every single if-statement because “it’s scalable, bro.”
And the worst part? They’re proud of this. They’ll post their over-engineered, inefficient mess on LinkedIn like it’s something to admire. They’ll call themselves “10x engineers” while their entire app collapses under 50 users because they never bothered to learn what a damn database transaction is.
Real Engineering > Vibes
Here’s a radical idea: Learn how things work before you build them.
The next time you’re about to cargo-cult some garbage architecture you saw on a Medium post, ask yourself: Do I actually understand this? If the answer is no, step away from the keyboard and pick up a damn book.
Because vibes won’t save you when your production database is on fire.